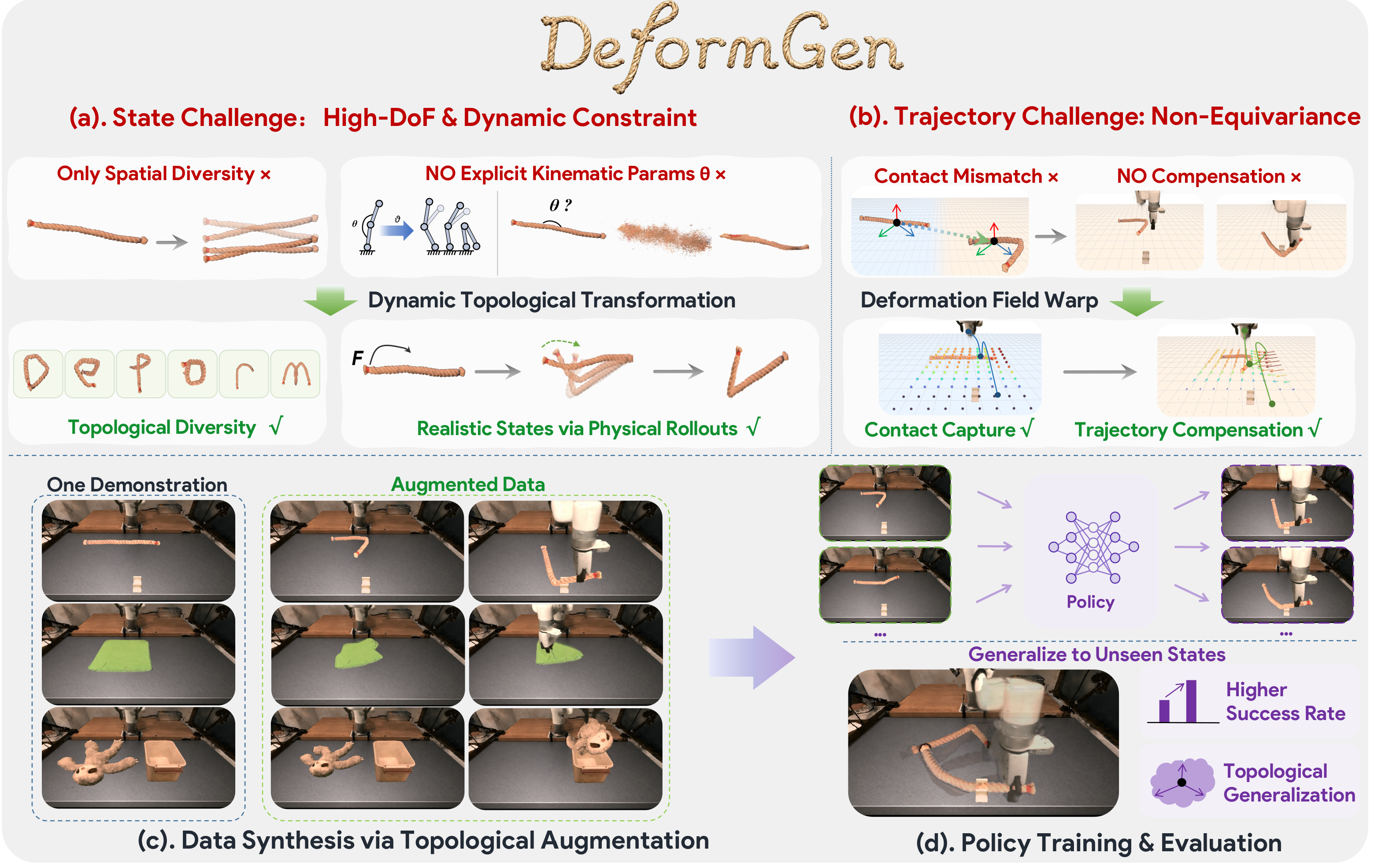
Demonstration augmentation is proposed for cost-efficient data acquisition, but existing methods are fundamentally limited in deformable manipulation due to two challenges: (1) the state space is high-dimensional with physics-induced constraints, making valid configurations impossible to reach via low-dimensional pose perturbations; and (2) trajectory transfer is non-equivariant, as material points no longer move rigidly together under deformation.
We present DeformGen, a dynamics-based augmentation framework that achieves topological diversity for deformable objects. For the state challenge, DeformGen expands the valid state distribution by applying localized physical disturbances and forward-simulating the dynamics to obtain topology-coherent, physically plausible deformable states.
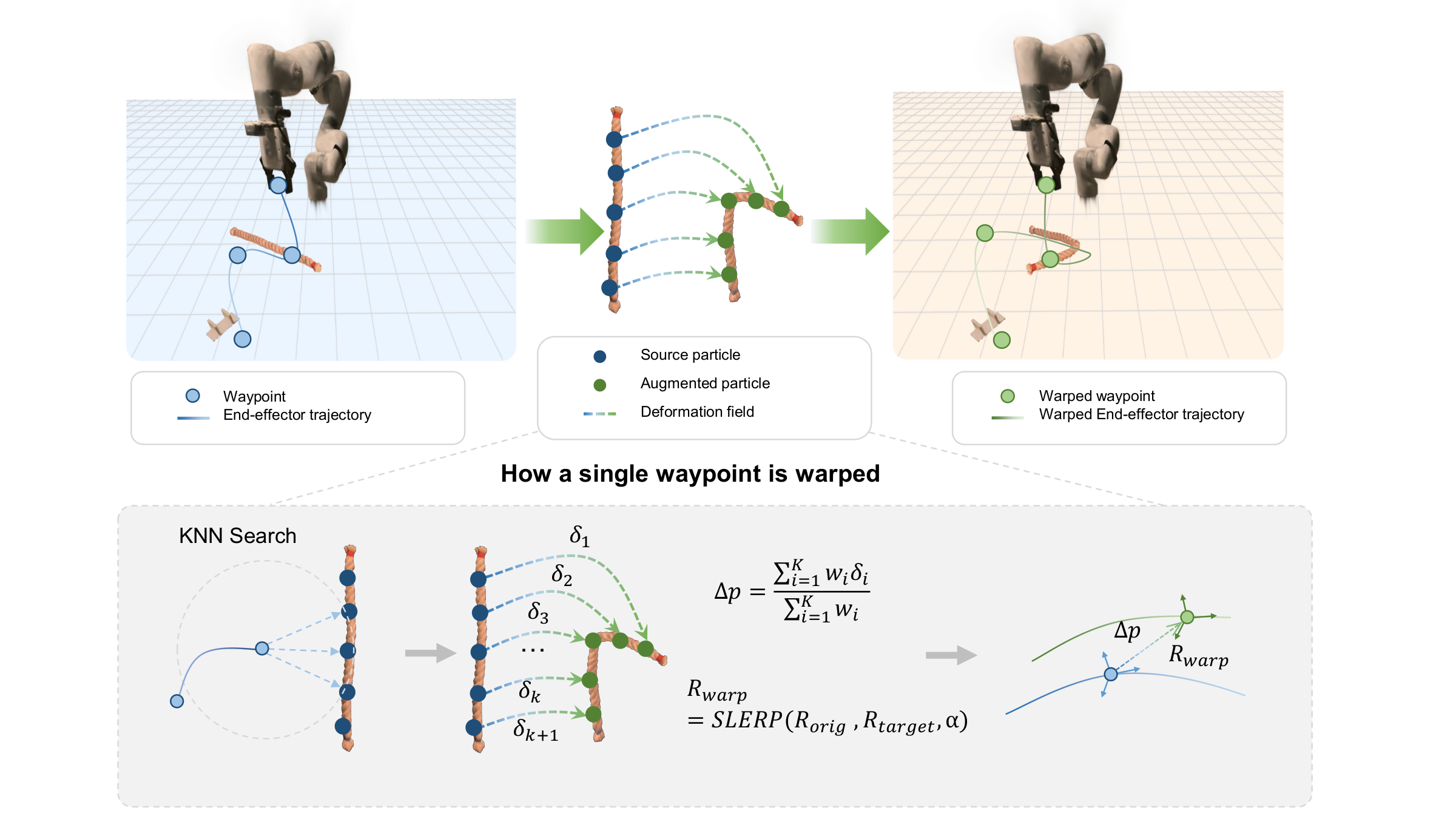
For the trajectory challenge, DeformGen transfers source manipulation trajectories via deformation-field warping, which lifts per-particle displacements into a continuous spatial function to adapt the end-effector trajectory consistently with the deformed geometry.
In this way, our method jointly augments the state distribution and its associated manipulation behavior. Experiments on high-fidelity deformable manipulation benchmarks show that DeformGen generally improves policy learning compared with training on the original demonstrations alone and with rigid-style augmentation baselines.